


Evidence Suggesting Voter Fraud in Wisconsin Senate Race
The good news is, the data shows that elections don't normally look like this. The bad news is, this makes Wisconsin look much worse.

[Originally Posted on X on Nov 11th, 2024)
Executive Summary
In Milwaukee County, a huge and improbable Dem vote dump flipped the race
In Dane and Winnebago countie, updates implausibly all improved Democrat vote share relative to prior votes. Updates got more extreme after GOP pulled ahead.

In Milwaukee, a large vote update of 109K votes, 83% favoring the Democrats, arrived at 3:31am on Wednesday and flipped the outcome of the race. This vote batch is improbable on a number of dimensions:
1. It is late at night
2. It differs from the 67% Dem vote share beforehand
3. It is 25% of all Senate votes cast in Milwaukee
4. It is a considerable fraction (3.2%) of votes in the overall race
5. The race was close beforehand (49.1% Dem vote share)
6. It flipped the outcome of the race

While each property has innocent explanations, the combination is highly unlikely. Only 8 updates are as extreme on the first 5 traits (including the Milwaukee President race). The Milwaukee Senate is the only update out of 46,489 that also flipped the outcome of the race.
In Dane and Winnebago, consecutive batches of vote updates manage to consistently improve Democrat vote share relative to the distribution of votes up to that point. This is analogous to flipping a coin and getting 22 out of 24 heads, and 14 out of 14 heads respectively.

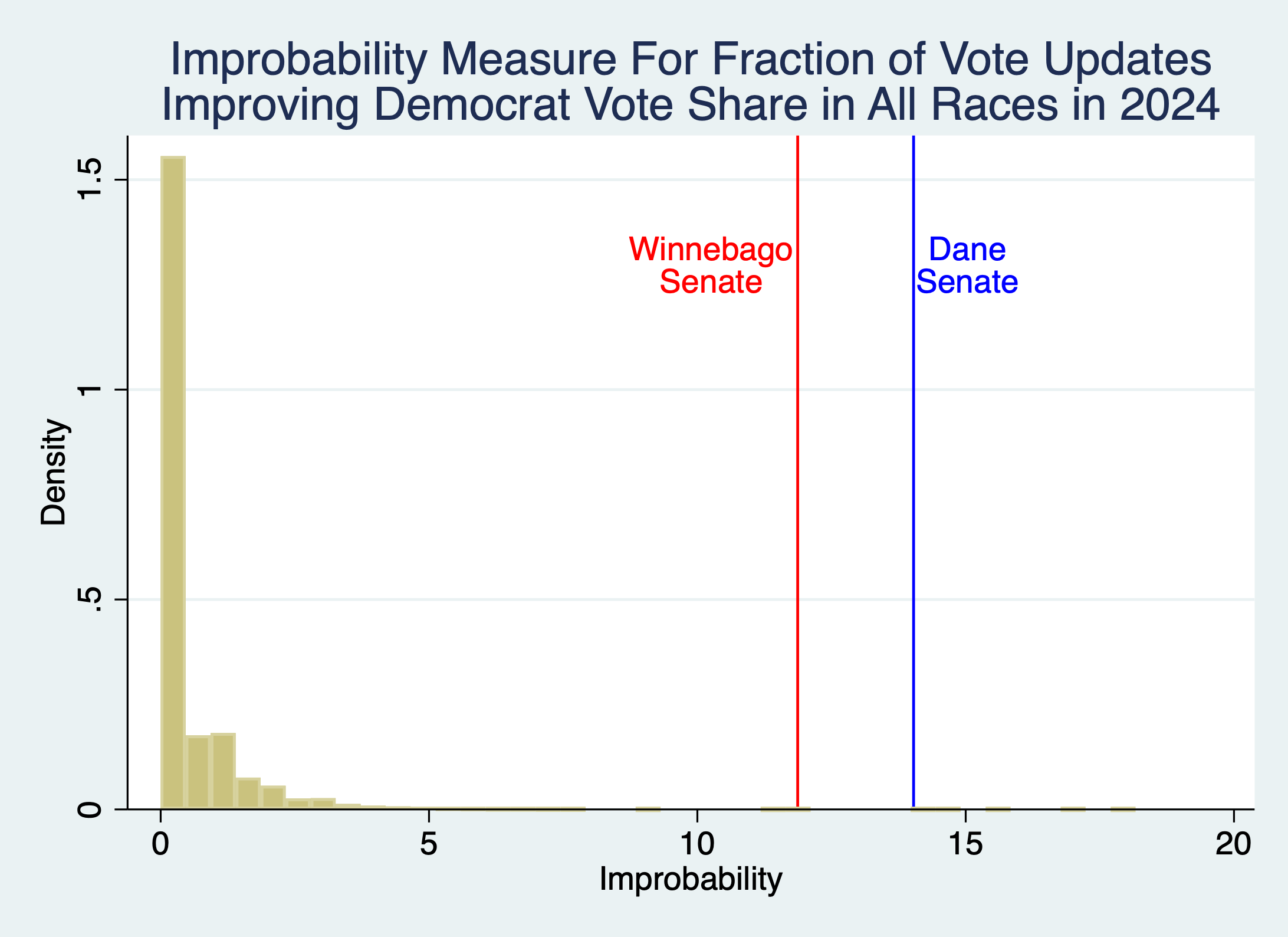
These outcomes are not explained by race type, county size, 2020 Dem vote share, or mail ballots. Dane and Winnebago have p-values for their Senate races of 0.00000081 and 0.000007, and 6 of the 9 most improbable sequences out of 1,175 races nationwide with at least 8 updates.
The size of the improvements also shows suspicious patterns over time. The amount by which new updates improved on old updates began to get larger at 9:56pm, once the GOP pulled ahead in the national race.


Dane went from updates being 4.8% above the previous average to being 6.6% above the previous average vote share (even though the new average was also higher). Winnebago went from a 3.0% improvement on the prior vote share to a 10.7% improvement on prior vote share.
All of these patterns individually have other potentially innocent explanations. But the combination of all of them, across different metrics and methodologies, across multiple counties, requires a very large set of coincidences to explain.
The methodologies used also suggest other suspicious instances worthy of further investigation. Richmond City, VA had had 38 out of 44 updates favoring the Democrats (p=10^-8), and a huge vote dump of 29% of the total as the 39th update, 3.5 hours after counting began.
Large and improbable updates occurred in a number of House races
Apache (AZ), Knox (IL), Ingham (MI), Midland (MI), Muskegon (MI), and Meriden (CT). In all cases except Meriden, the update favored the Democrat.
Details
2.1 The Large Update in Milwaukee County
Let’s begin with the Milwaukee Update. First we’ll highlight all the aspects that seem surprising, and then we’ll see how it compares to 46,489 vote updates nationwide across House, Senate and Presidential races up to 12:55pm on November 7th
The update occurred at 3:31am CT on Nov 6th in AP data. Adjusting for time zone differences, Milwaukee’s 3:31am update comes later than 93.3% of other vote updates in America. If we limit to vote updates after midnight, there are 4,649 votes that come as late or later.
While being late is not suspicious on its own, it is worth noting that being the last to announce your count is very important if you want to swing a race by fraud. Because it is only at the end of the race that you know how many votes you need.
Second, the 108K vote update had a 2 Party vote share that was almost 16 percentage points higher than Milwaukee’s Senate votes up to that point (83% vs 67%). The 16% swing to the Democrats puts it in the 91.7th percentile of vote updates that most favored the Democrats.
If we start with vote updates after midnight and limit ourselves to 15% swings for either party (approximately the 91st percentile of favoring Dems), we get 1,405 updates – 879 favoring Democrats, and 526 favoring Republicans.
The 108K votes in the new batch are a large number compared with 335K votes up to that point in the Milwaukee Senate race. The single batch represented 24.5% of all Senate votes that Milwaukee announced in total.
By themselves, large updates are not suspicious at all - many counties announce most or all of their count at once. But it becomes more unusual given that a) it was late at night, and b), there were many updates beforehand. Mostly, counts are slowing over time, and late updates are small.
Of updates after midnight, Milwaukee is at the 70.9th percentile of update size. But this was the 15th update in Milwaukee. Large updates are much less concerning if they’re one of the first updates, when count rates are generally high as all the precincts are counting at once.
If we drop all post-midnight announcements which were the first one for the county, Milwaukee is now in the 86.9th percentile of size. It is the 92.7th percentile of size for 5th or later announcements, and the 97.9th percentile of size for 10th or later announcements.
Taking our post-midnight announcements with large swings, if we also require them to be above the 80th percentile of size among second-or-subsequent announcements, we get 150 total cases – 106 favoring Democrats, and 44 favoring Republicans.
Fourth, the size relative to the overall race (not just the county). The Milwaukee update is 3.2% of all votes in the state. Updates that are small relative to the overall race are less concerning. If we look at second updates after midnight, this makes Milwaukee at the 94.4th percentile.
If we limit ourselves to all four screens, we get a total of 25 unusual cases. 17 of these favor Democrats. 8 favor Republicans. Some of these just seem weird in ways where it’s not clear what’s going on.
Kootenai, ID, has 4 updates in two races, with two favoring Republicans and two favoring Democrats. Wayne, MI, hardly a Republican stronghold, has two House updates favoring Republicans, where previous Democrat-heavy counts were followed by two updates close to 50/50.
So an important final screen is for the race to actually be close before the update. Weirdness without clear motivation for fraud may still indicate something amiss, like irregularities in a local race affecting a national one. But probably it’s just odd counting processes.
The statewide race was 49.12% for the Democrats beforehand.
The update tipped the race to 50.25% Democrat, and they ultimately won.
If we limit ourselves to cases where the race was also close beforehand (defined as Democrat Two Party vote share between 45% and 55%, we get 8 cases total, with 7 favoring the Democrats. Two are in Milwaukee (Senate and President), and these are the closest races of the 8.
The others are House races in Apache (AZ), Knox (IL), Ingham (MI), Midland (MI), Muskegon (MI), and Meriden (CT )(the only one favoring Republican). These seem worth investigating, but the line for “suspicious” is very gray – vary the cutoffs and you get a different list.
Being mostly House races is interesting given the incentives involved. If you control a county, it is hard to be big enough to change a statewide race, and co-ordinating with other counties risks many ways to end up in jail. But it is easier to be big enough to swing a House race.
There is one final important screen. Did the update actually change the outcome?
Of the 8, this is true in exactly *one* case, out of the 46,489 we began with – the Milwaukee Senate Race. Your gut instinct was not deceiving you. This is not how elections normally work in America. All of this is in addition to great work by @TonerousHyus documenting implausible levels of turnout in many Milwaukee precincts, which is another independent type of anomaly. You can decide for yourself if you think this rises to the level of “too unlikely to be reasonably innocent”.
2.2 Implausible Update Streaks in Dane and Winnebago Counties
Now, let us turn to Dane and Winnebago. Their updates were unusual in a different way – they had many smaller updates, where each favored the Democrats more than the average up to then. It is surprising for each update to keep getting better for the Democrats over and over.
We don’t know the exact counting process at play. But suppose that different wards count votes and periodically notify the county. At some points you’ll get more updates from places that favor Democrats, and at other times more updates will be from Republican areas.
If you’re counting votes in a random order, you expect each update to be a coin flip relative to the previous average. If you observe long streaks of “heads” in a row, it implies that counting is occurring non-randomly, with strongholds for one party only being counted later.
Now, there are many innocent reasons this might occur, and I’ll test as many as I can. But Dane County had 22 out of 24 updates that favored the Democrats, and Winnebago had 14 out of 14. Taking into account all the real-world reasons for non-randomness, how likely is this?
It is extremely unlikely. The p-values for Dane and Winnebago are 0.00000081 and 0.000007 (10^-7 and 10^-6). Your gut instinct is right again – 22 out of 24 heads is in fact very weird, even if these aren’t perfectly independent 50/50 coin flips. (FN1)
Like testing coin flips, the test doesn’t work well for counties that only have a few updates. But among 1,175 counties with at least 8 updates (where p-values can be below 0.01), the 3 races each in Dade and Winnebago have 6 of the 9 lowest p-values, and are enormous outliers.
Parenthetically, Richmond City, VA is the most improbable of all. The Richmond City, VA Senate race had 38 out of 44 updates favoring the Democrats (p=10^-8), and a massive vote dump of 29% of the total as the 39th update, 3.5 hours after counting began.
As I said in 2020, Virginia is my guess for “state with the most voter fraud that you rarely hear about”.
https://shylockholmes.substack.com/p/repost-last-thoughts-on-voter-fraud
If you’re a stats nerd, you probably have many legitimate questions/concerns about the graph of Dane and Winnebago. I’ll give some answers briefly below, and footnote the detail until the end. I’m sure I’ve missed some weaknesses, but I’ve tried to address as many as I can.
- I’m plotting -1*ln(p-value) for a binomial test. Large numbers are more improbable
-By comparing with other counties, we already take into account average levels of any real-world reasons why later updates would favor Democrats, including ones that would bias the test (FN 2)
- I’m explicitly controlling for some of the biggest drivers of vote updates favoring the Democrats: the office being voted on, county size, and Biden 2020 vote share. So these can’t be the reasons that Dane and Winnebago differ from the average. (FN 3)
-Where we can measure it, absentee ballot proportion in 2020 turns out to not matter (FN 4)
-Pretty much whatever variables you use to forecast update probabilities don’t change the answer a great deal, because 22 out of 24 heads is just so extreme (FN 5)
-The lack of independence isn’t coming from Dane or Winnebago having one massive early update that permanently shifts the average relative to later updates. The updates have decently consistent size, and the larger updates don’t have unusual vote shares (FN 6)
-The p-values are far too extreme to be explained just by choosing the most unusual cases out of 1,175 counties, (FN 7)
In layman’s terms, what this shows is that it is extremely unusual to have so many consecutive updates all increasing the Democrat vote share relative to what came before – not just weird intuitively, but also weird empirically relative to everywhere else in America.
To understand what’s going on, it is helpful to just plot all of the updates in both counties. I’m showing two things. First, the two-party vote share for the Democrats in each update (the points). Second, the overall-two-party vote share for the county the line.


The graph shows what we describe above – every time the point is above the line, the new batch is better than the race up to that point. Lo and behold, they’re nearly all above the line.
But the graph also shows unusual patterns in *how much* the points are above the previous average, not just *whether* they were above the previous average. It is visually apparent that the updates get much more extreme at 9:56pm when the Republican pulls ahead in the state-wide race.
If we test this relationship formally, the p-value for this being due to chance is 0.009 in Winnebago. In Dane, the updates are noisier, and with few data points, the p-value is only p= 0.408. But some of the updates are very extreme, over 90% vote share for the Dems.
Also, bear in mind that this change is taking place at the same time in both places This holds true, even though the time taken to count the updates is very different in the two places, ending after about 5 hours in Dane vs 13 in Winnebago.
It is worth taking stock of the big picture here. Each individual test has weaknesses. But the sheer number of different implausible aspects, in different parts of Wisconsin, measured with different methodologies, make it very hard to have confidence in the election outcome.
The good news is that the data reveals that most outcomes in American elections don’t look like this.
The bad news is, that fact makes the Wisconsin senate races in Milwaukee, Dane and Winnebago look much worse.
FN1: Interpretation of Binomial Test Results
The p-values are for a test of the hypothesis that the distribution of outcomes is independent and driven by the assumed probability of each outcome favoring the Democrats. The test can fail to be a good evaluation if we estimate the wrong probability, or if outcomes are correlated for other innocent reasons we fail to model.
In the latter case, the p-value would still be correct – the interpretation would just be that the count is non-random for innocent reasons that we failed to interpret correctly. Indeed, “rejecting the independence of vote updates” admits of different interpretations, which is what the rest of the tests aim to understand.
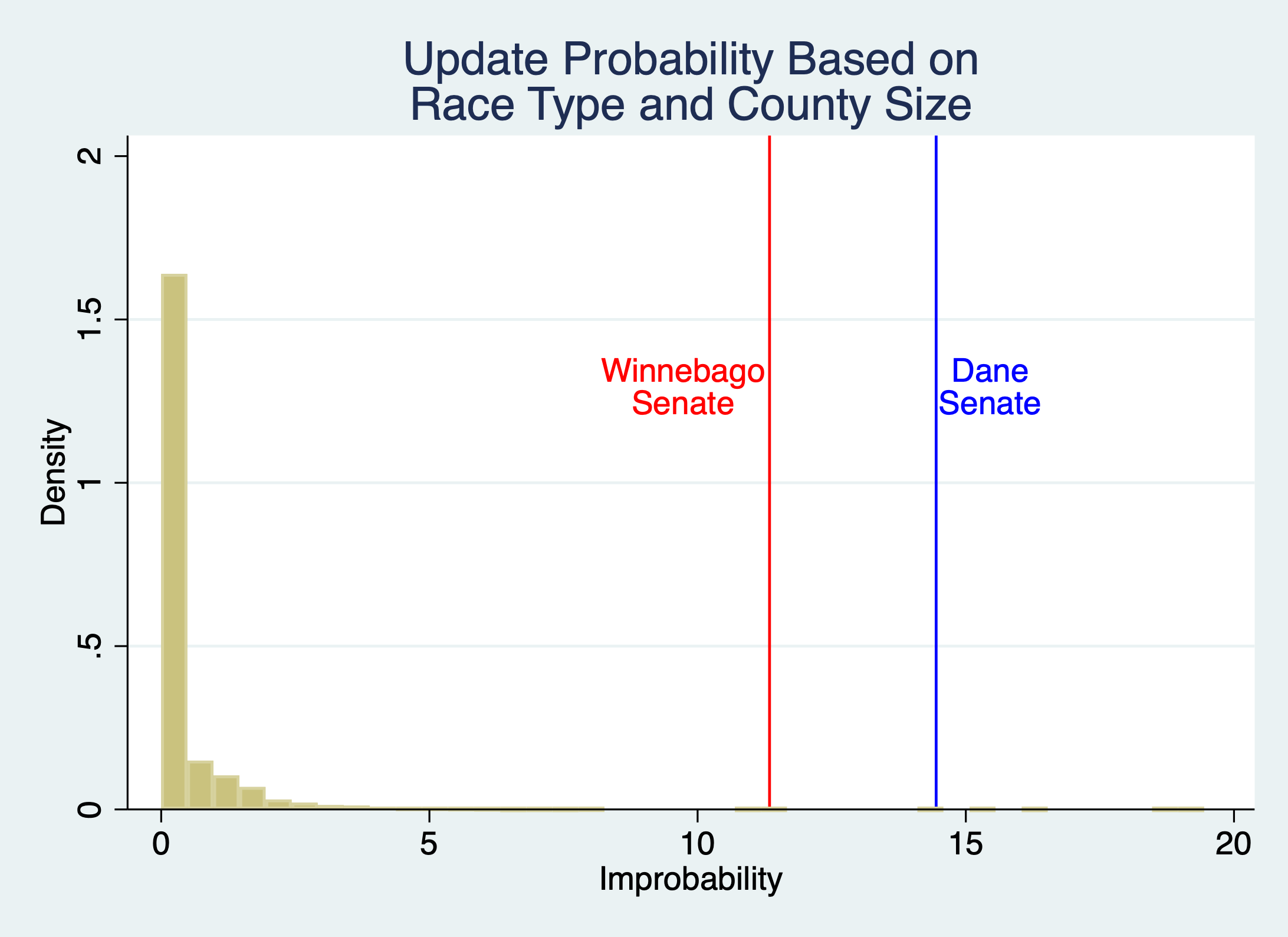
The graph converts these p-values into “improbability measures” by taking -1*ln(p-value), so that lower p-values have higher values. There is a question of interpretation whether one ought to include counties with only a small number of updates, since by necessity their p-values cannot be very small. I include them in the main graph, but the picture is similar if only races with at least 8 updates are included, so that in principle the county could reach 1% significance.

FN2: Importance of Real World Benchmarks
The p-value for the binomial benchmark is interpretable under the assumptions of the binomial test, even if this were the only data available. It suffers if the assumptions of the test are incorrect. But if these assumptions are violated everywhere, it would not explain why these counties look unusual in the distribution. Being the 6 of the 9 most extreme outcomes out of 1,175 is a different form of p-value. In some sense, this is tautological, because something has to be at the extremes of the distribution. But the fact that these datapoints are obviously extreme outliers relative to this distribution is not at all tautological. It further strengthens the interpretation that, whatever weaknesses the test assumptions may have, Dane and Winnebago look extremely different to the rest of America for some reason.
FN3: Determinants of Probability of Update Probability.
I use a regression of all updates to get an estimated probability for each race of the chances that an update is expected to favor the Democrats. The baseline version included in the graph above includes as predictors indicator variables for the type of race (President, Senate, House), the natural log of the total number of votes cast in the presidential election in 2024 (a measure of county size), and the 2020 Two Party Vote Share for Biden in that county.
The test thus assumes that outcomes are independent given the base rate that these predictors give for the chances that each update will favor the Democrats. In other words, if Dane and Winnebago are different from other counties for innocent reasons, it is due to factors other than the ones above.
FN4: Effect of Absentee Ballots
MIT Election Lab unfortunately only has data on absentee/mail ballots in 2020 for a subset of states and counties, and these do not include any in Wisconsin. Absentee or mail ballots are one of the most frequently cited reasons for unusual patterns in the timing of vote counts.
However, when the fraction of mail/absentee ballots is included as a predictor of whether later votes favor Democrats more than early votes, it shows no significant effect, with a p-value of 0.718. By contrast, the 2020 Biden vote share and log county size are both significant at 2*10^-5 and 2*10^-6 respectively. In Richmond City, the most suspicious vote distribution, including absentee ballots alongside the base prediction variables changes the p-value by only a small amount, from 5*10^-8 to 1*10^-6.
This suggests that absentee ballots are unlikely to be the driver of differences, whatever level of absentee ballots the counties in Wisconsin have.
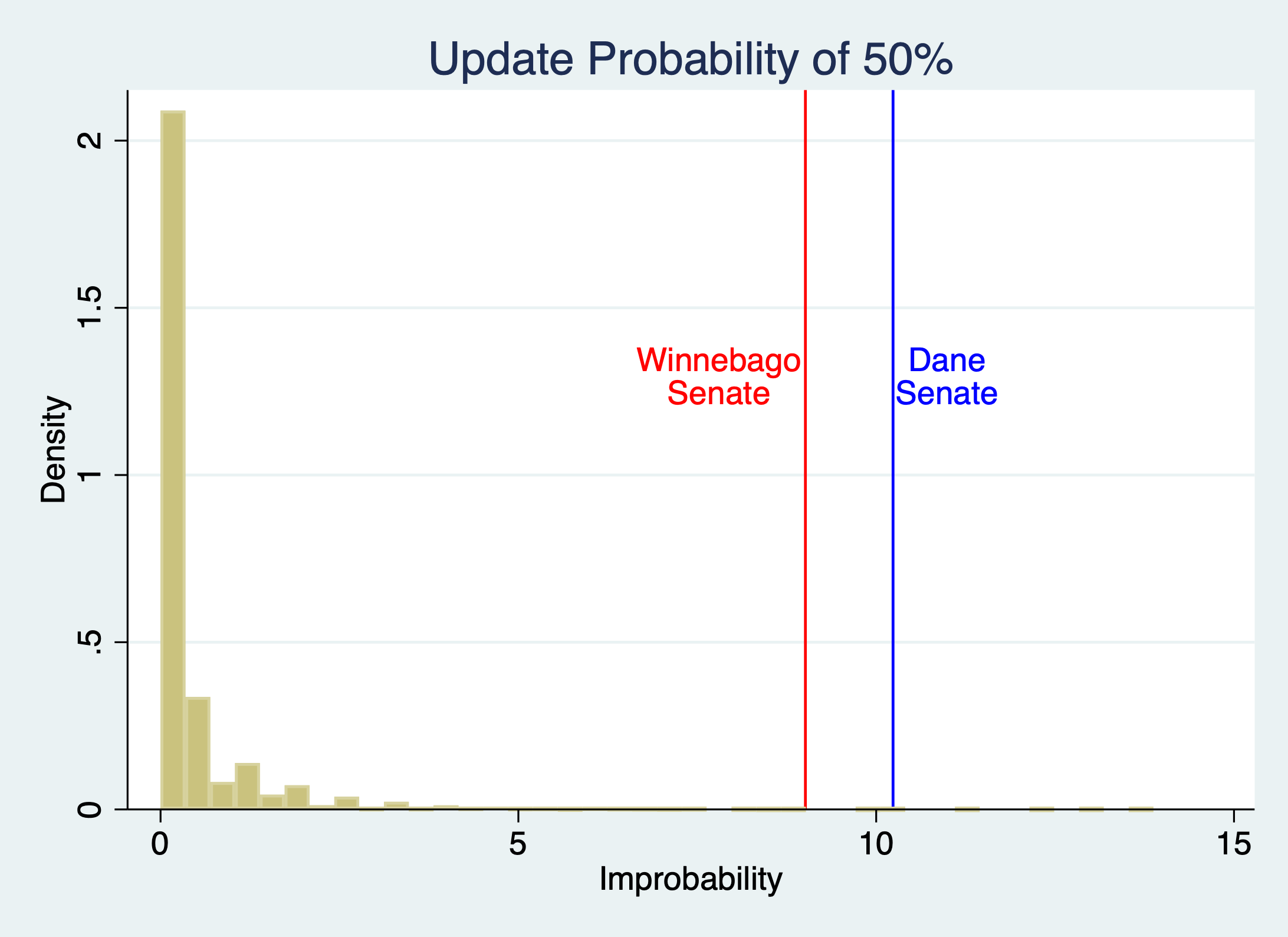
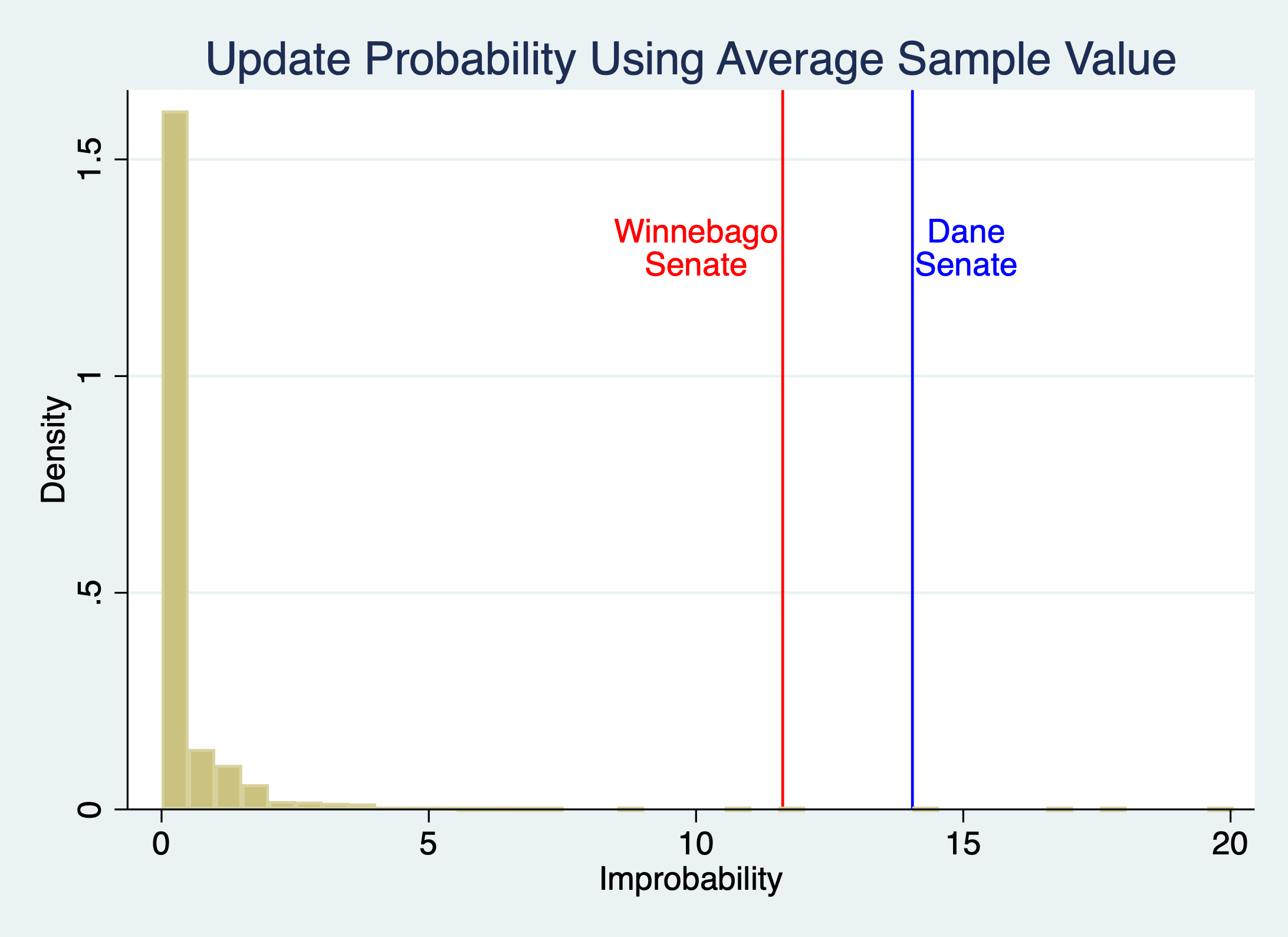
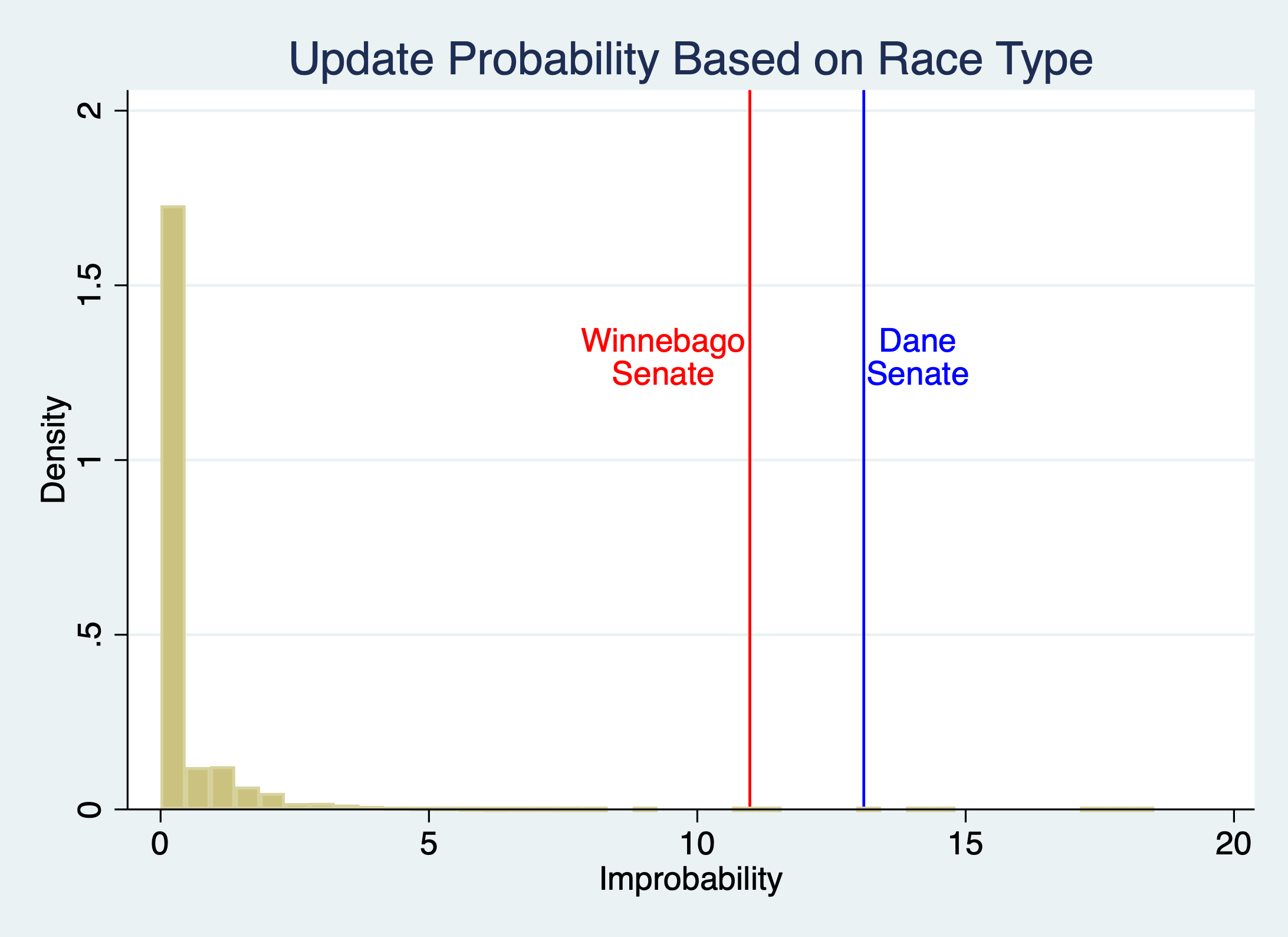
FN5: Different Models of Estimating Update Probabilities
Using different versions of controls for forecasting the update probabilities for the binomial test changes the p-values somewhat, but nowhere near enough to alter the conclusions about the implausibility of Dane and Winnebago. The controls in the main specification are intuitive, but also not needed.
In terms of reduced sets of controls, one can use::
-A 50% probability: p = 0.0000359 (Dane), 0.0001221 (Winnebago)
-The unconditional average probability (41.5%): p = 7*10^-7 (D), 9*10^06 (W)
-Probability controlling for race type( 43.4%) p =2*10^-6 (D), 1*10^-5 (W)
-Probability controlling for race and county size (D: 40.7%, W: 42.3%): p=5*10^-7 (D), 1*10^-5 (W)
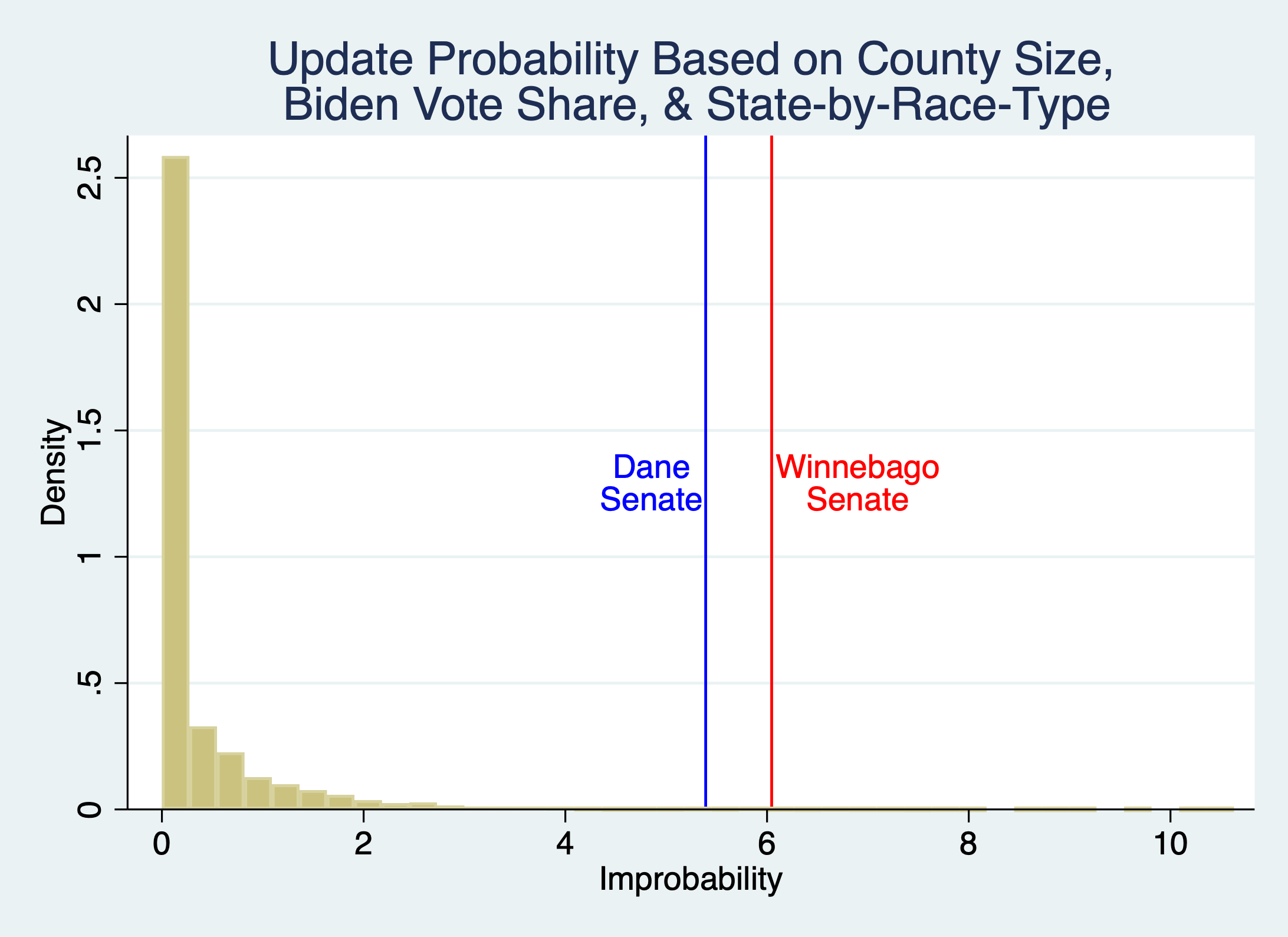
In terms of adding extra controls, one can also add a fixed effect for each state. This is arguably too conservative, because it then strips out the higher average level of fraud in Wisconsin, along with everything else about the state. But even doing so gives:
-Probability controlling for race, county size, and state (D; 64.2%, W:62.1%): p-value = 0.005 (D), 0.002 (W)
One can even control for state-by-race fixed effects, so stripping out the effects of the Wisconsin Senate race specifically
-Probability controlling for county size, and state-by-race (D: 64.0%, W: 61.7%): p-value = 0.005 (D), 0.002 (W)
Across every specification, including the quite conservative ones, the p-values are much lower than chance would predict.

FN6: Effect of Batch Sizes
An obvious way that the independence assumption of updates on the overall Democrat vote share would be violated would be if there were one large vote dump that looked unrepresentative. In such a case, subsequent updates would all look different from this average, but this would mostly be measuring the effect of the one anomaly. It still may be a source of concern, but the usefulness of the binomial test as a way of showing it would be considerably called into question.
An inspection of the number of votes per batch, and the 2 party vote share, shows that this is not driving the effect. In both Dane and Winnebago, while there is some variation in batch size, there is no one large and unrepresentative update – the largest early updates look in line with the other surrounding updates in terms of vote share.


FN7: Effect of Comparing Many Vote Outcomes on p-values
One potential problem with the p-values computed for Dane and Winnebago is the multiple comparisons problem. That is, these observations were not true ex-ante predictions about locations of fraud (although expecting to find fraud in Milwaukee arguably *was* an ex-ante prediction). In other words, when one selects on the most extreme outcome, one cannot compute a p-value as if the observation were randomly chosen.
This is a valid concern, but a simulation shows that this effect is far too small to explain the results I find, if updates are in fact independent. To show this, I take the estimated probabilities and number of updates in the race corresponding to each of the races in the sample (i.e. those with at least 8 updates total). Then, I simulate a Bernoulli random variable with this probability for each outcome, and compute the binomial probability for each sequence. I do this 1,000 times.
I then take the distribution of 1,000 p-values corresponding to the same rank in the observation list as the Dane and Winnebago Senate races (6th and 8th respectively). I then compute the distribution of simulated p-values for the equivalent-ranked observation, and compare it to the actual p-values. In other words, this is estimating the effect that while Dane and Winnebago didn’t have to be the most extreme outcomes, something did, even if they all just occurred by chance.
These simulations show that the effect due to being the 6th most extreme value out of 1,175 is very small relative to the observed p-values. None of the 1,000 simulated p-values comes close. Indeed, when comparing the realized log p-value for the two real races versus the simulated distribution, they are between 28 and 30 simulated standard deviations away from the simulated mean. In other words, the outcomes are far more extreme than simple multiple comparisons would predict.
Votes are not counted at random. Further, you would likely get a similar result but opposite conclusion if you had done this test at a different time point (~23).
This analysis is extremely flawed. Comparing vote count updates to coin flips suggests the updates are independent events and that the votes are counted randomly, as if they all go in a big pile and shuffled before being randomly counted. That's not how votes are counted! For one, absentee & early vote ballots take longer to tally than in-person ballots, especially in places like Milwaukee that have a single 'central counting' place. People who vote early/absentee are an entirely different population from those who vote on the day of in-person!